通过图例来解释剪枝方法
文献参考:decision
tree-By 天泽28
预剪枝(pre-pruning):预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,若果当前结点的划分不能带来决策树模型泛华性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
后剪枝(post-pruning):后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛华性能的提升,则把该子树替换为叶结点。
一、预剪枝 ( pre-pruning
)
注意图片显示不出来是因为被
墙 了,因此需要科学上网!
也有说是DNS污染了,这里简要介绍一下DNS
污染:网域服务器缓存污染(DNS cache
pollution),又称域名服务器缓存投毒(DNS cache
poisoning),是指一些刻意制造或无意中制造出来的域名服务器数据包,把域名指往不正确的IP地址。一般来说,在互联网上都有可信赖的网域服务器,但为减低网络上的流量压力,一般的域名服务器都会把从上游的域名服务器获得的解析记录暂存起来,待下次有其他机器要求解析域名时,可以立即提供服务。一旦有关网域的局域域名服务器的缓存受到污染,就会把网域内的计算机导引往错误的服务器或服务器的网址。
此处省略求解决策树的过程,分类的操作除了利用信息增益还有信息增益率和基尼系数等,放心!不影响理解的。
现在只考虑剪枝,只需要知道下面的判断是通过剪枝前后两个模型载入测试数据得到的结果与真实值的一个精度比较,来衡量是否进行剪枝,剪了也就选定了精度高的模型,精度越大越好!
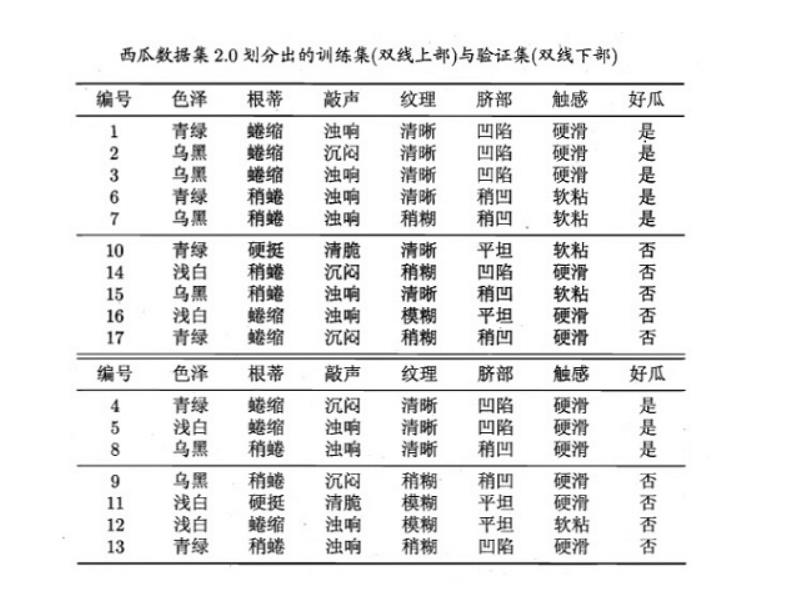
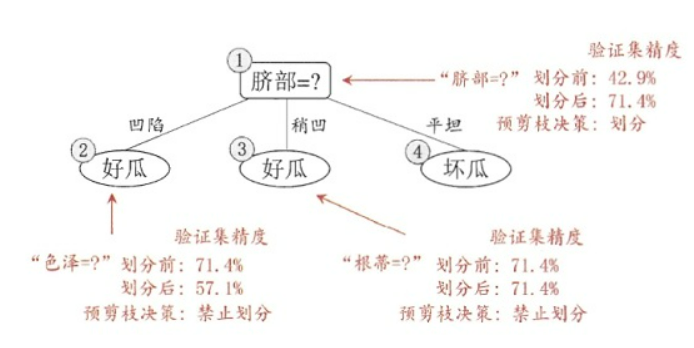
因为色泽和脐部的信息增益值最大,所以从这两个中随机挑选一个,这里选择脐部来对数据集进行划分,这会产生三个分支,如下图所示:
但是因为是预剪枝,所以要判断是否应该进行这个划分,判断的标准就是看划分前后的泛华性能是否有提升,也就是如果划分后泛华性能有提升,则划分;否则,不划分。
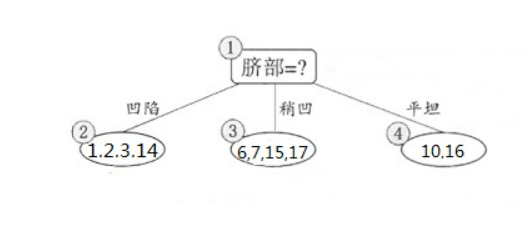
下面来看看是否要用脐部进行划分,划分前:所有样本都在根节点,把该结点标记为叶结点,其类别标记为训练集中样本数量最多的类别,因此标记为好瓜,然后用验证集对其性能评估,可以看出样本{4,5,8}被正确分类,其他被错误分类,因此精度为43.9%。划分后:
划分后的的决策树为:
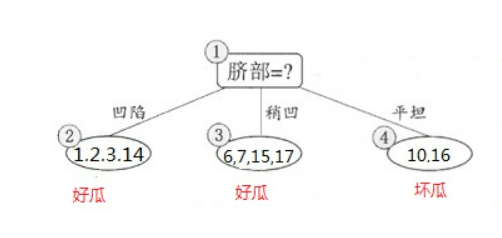
则验证集在这颗决策树上的精度为:5/7
= 71.4% > 42.9%。因此,用脐部进行划分。
接下来,决策树算法对结点
(2)
进行划分,再次使用信息增益挑选出值最大的那个特征,这里我就不算了,计算方法和上面类似,信息增益值最大的那个特征是“色泽”,则使用“色泽”划分后决策树为:
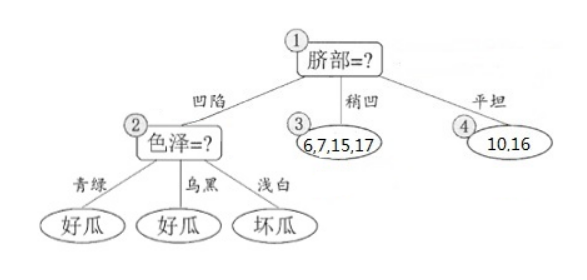
但到底该不该划分这个结点,还是要用验证集进行计算,可以看到划分后,精度为:4/7=0.571<0.714,因此,预剪枝策略将禁止划分结点
(2) 。对于结点 (3)
最优的属性为“根蒂”,划分后验证集精度仍为71.4%,因此这个划分不能提升验证集精度,所以预剪枝将禁止结点
(3) 划分。对于结点 (4)
,其所含训练样本已属于同一类,所以不再进行划分。
所以基于预剪枝策略生成的最终的决策树为:
总结:
对比未剪枝的决策树和经过预剪枝的决策树可以看出:预剪枝使得决策树的很多分支都没有“展开”,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。但是,另一方面,因为预剪枝是基于“贪心”的,所以,虽然当前划分不能提升泛华性能,但是基于该划分的后续划分却有可能导致性能提升,因此预剪枝决策树有可能带来欠拟合的风险。
二、后剪枝 ( post-pruning
)
后剪枝就是先构造一颗完整的决策树,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛华性能的提升,则把该子树替换为叶结点。前面已经说过了,使用前面给出的训练集会生成一颗(未剪枝)决策树:
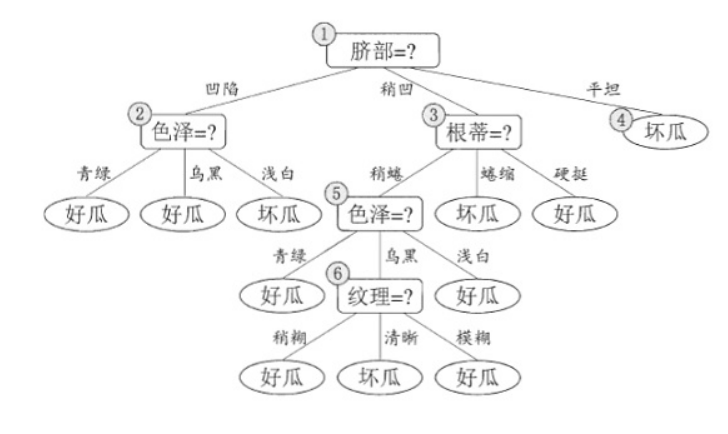
后剪枝算法首先考察上图中的结点
(6),若将以其为根节点的子树删除,即相当于把结点 (6)
替换为叶结点,替换后的叶结点包括编号为{7,15}的训练样本,因此把该叶结点标记为“好瓜”(因为这里正负样本数量相等,所以随便标记一个类别),因此此时的决策树在验证集上的精度为57.1%(为剪枝的决策树为42.9%),所以后剪枝策略决定剪枝,剪枝后的决策树如下图所示:
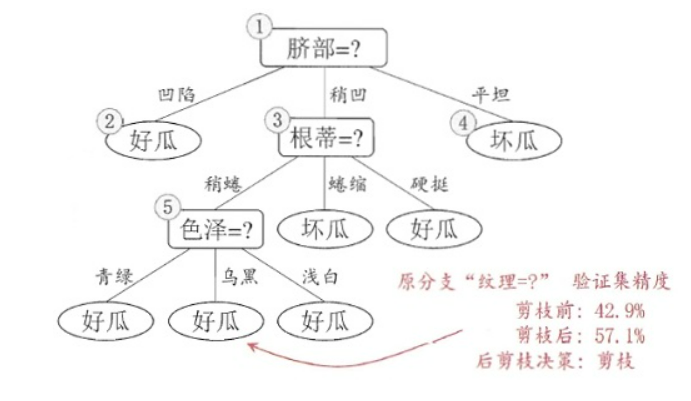
接着考察结点
5,同样的操作,把以其为根节点的子树替换为叶结点,替换后的叶结点包含编号为{6,7,15}的训练样本,根据“多数原则”把该叶结点标记为“好瓜”,测试的决策树精度认仍为57.1%,所以不进行剪枝。
考察结点 2
,和上述操作一样,不多说了,叶结点包含编号为{1,2,3,14}的训练样本,标记为“好瓜”,此时决策树在验证集上的精度为71.4%,因此,后剪枝策略决定剪枝。剪枝后的决策树为:
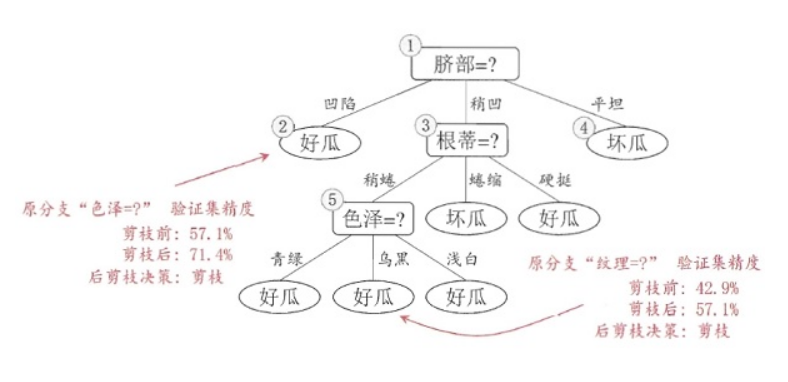
接着考察结点 3
,同样的操作,剪枝后的决策树在验证集上的精度为71.4%,没有提升,因此不剪枝;对于结点
1 ,剪枝后的决策树的精度为42.9%,精度下降,因此也不剪枝。
因此,基于后剪枝策略生成的最终的决策树如上图所示,其在验证集上的精度为71.4%。
总结:对比预剪枝和后剪枝,能够发现,后剪枝决策树通常比预剪枝决策树保留了更多的分支,一般情形下,后剪枝决策树的欠拟合风险小,泛华性能往往也要优于预剪枝决策树。但后剪枝过程是在构建完全决策树之后进行的,并且要自底向上的对树中的所有非叶结点进行逐一考察,因此其训练时间开销要比未剪枝决策树和预剪枝决策树都大得多。
----以上为个人思考与见解,有误请指点,有想法也可联系交流
谢谢观看!
决策树
—— C4.5 (一) 算法简述
决策树
—— C5.0和CART
